
C言語は ポインタ が難しい、ポインタがあるから挫折した、なぜポインタが必要なのかわからないという人は多くいるのではないでしょうか。今回はC言語の鬼門の一つポインタについて、誰にでも分かっていただけるように、全力で説明したいと思います。
私も学生の頃、ポインタについて全く理解できていませんでした。そもそもなぜ必要なのかを理解できていなかったからだと思います。
なお、本記事の内容は個人的な見解も含むため、誤っている情報もあるかもしれません。そのような時はコメントで教えていただきたいです。
そもそもなぜC言語が使われるのか?
なぜ、組み込みではC言語が使われるのか
そもそも、なぜ組み込みの現場では今でもC言語が使われるのでしょうか?
C言語が現役で存在する→仕事で使う→ポインタを理解しないといけない
というのがポインタを学ぶモチベーションになるとすると、まずC言語が使われる理由から知ることから初めて行く必要がありそうです。
C言語の特徴も絡めて以下で説明していきます。
シンプルで処理が高速だから
非常にシンプルでマシン語(アセンブラ)に近い処理を記述することができます。
そのため、コードから吐き出されるバイナリは他の言語に比べて無駄な処理が少なく、高速に処理を行えます。
ハードウェアの制御でもたもた動いていたら、そのソフトの上で動くミドルウェア、アプリは非常に迷惑ですよね。ドライバやkernelはとにかく迅速に処理をこなす必要があります。
そういった点でC言語で記述することは便利です。
無駄な機能がないから
Javaなどの高級言語だとヒープ再利用のためのガベージコレクションが動いたり、暗黙のコードが生成されたりと実装者が制御できない機能が備わっていることがよくあります。
そういった機能がC言語にはありません。無駄な機能がないということは使用するROMやRAMの量を減らすことができます。
リソースの少ない小さなマイコンで動かすコードはCで記述することが多いです。
メモリアドレスを直接指定してデータアクセスを記述できるから
この3つ目がC言語のポインタという概念と大きくかかわる点になります。
CPUはアドレスと呼ばれる空間とそこに存在するデータを扱います。アドレスの番地は数値で表現され、1番地に対して1byteのデータが割り付けられています。
CPUはそのアドレスに何かしらのデータを読み書きすることでハードウェアを動かしたりプログラムを動かしたりしています。
そして、このアドレスに対するデータの読み書き操作をC言語は直接記述することができます。この記述方法としてポインタという概念が使われているわけです。
ではもう少しCPUのアドレスとデータという世界を考えてみましょう。
CPUの世界を理解する
ポインタを理解する上で必要となるCPUの世界を簡単に説明します。CPUには64bitとか32bitとか聞いたことあるかと思います。
64bitの方が早いんでしょ?くらいにしか思わないかもしれませんが、このbit数がポインタを学ぶ上では大事になります。ここでは32bitを例にお話しします。
アドレス空間とは
先ほど、CPUはアドレスを指定してそのアドレスにあるデータを読み書きできると説明しました。この読み書きできる領域範囲をCPUのアドレス空間といいます。
このアドレス空間は何番地から何番地まであるのでしょうか?ここでCPUのbit数が関係してきます。
32bit CPUは32bitで表現できるアドレス空間を扱うことができます。32bit=4byteですから、4byteで表現できる範囲の番地を扱えるということです。
すなわち、扱える番地の範囲は4byteで表現できる0x00000000 ~ 0xFFFFFFFF となります。CPUはこの範囲のいずれかの番地を指定することができるのです。
アドレス空間には何があるのか
CPUはアドレス番地を指定してデータを読み書きすることでプログラムを実行しているという話は前述しました。では、指定したアドレスの先には具体的に何があるのでしょうか?
答えは「何かがあることもあれば、何もないこともある」です。
どういうことか簡単にいうと、作る人が決めるので、何があるのか決まっていないということです。では何かがある場合、どいういうものがあるのか例を挙げて説明します。
プログラムが書き込まれているROM、データを読み書きできるRAM、この辺がすぐ思いつくかもしれません。CPUはROMのアドレスからデータを読みだしてそれを命令と解釈して実行したり、実行するための情報を保持するためにRAMのアドレスにデータを書き込んだりしています。
また、ペリフェラルをコントロールするための機能(レジスタと呼ばれる)だったりとか、PCIEのバスに割り当てられている領域だったりとか、CPUが制御すべきものが割り当てれています。
Windows PCのデバイスマネージャーでそのイメージをつかむこともできます。メモリの範囲というところがここでいうアドレスの範囲で、この範囲にGPUデバイスが割り当てられていることがわかります。
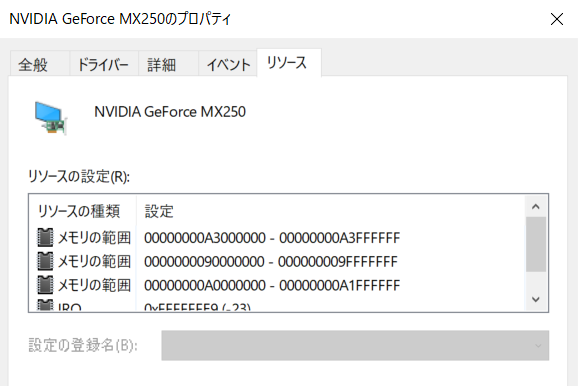
32bit CPUだど4GB以上のメモリをつけても使えないという話を聞くことがあるかと思います。
4GBは 4,294,967,296B=0x1_0000_0000 ですので、これを32bit CPUのアドレス空間に割り当てると0x00000000~0xFFFFFFFFの範囲ぴったり必要となってしまいます。
CPUはメモリだけ見えてればいいわけではないので、全ての空間をRAMに使用することはできません。それはすなわち、4GBRAMの全ては空間不足で使えないということになります。
C言語のポインタを理解する
C言語のポインタに話を戻します。
一般的にC言語でポインタを学ぼうとするとCPUの話には触れず、「ポインタ変数は・・」とか「変数の型は・・」とかから始まり、徐々に「関数の引数で値を受け渡す時は・・・」とか、「配列へのアクセスは・・」とかに進み、「リスト管理で間にリストを差し込むときは・・」とか「データのキュー管理は・・」といったあたりで嫌になり混乱して終わります。
しかし、ここではそのような話はしません。
ここまで説明してきた「CPUアドレスという概念」を踏まえ、C言語のポインタがどういう機能かというのを一言でいうと
ポインタはCPUのアドレスに対して直接データの読み書きができるC言語の機能
となります。このポインタを使えばCPUからROMだってRAMだってデバイスだってすきなアドレス空間に好きなようにアクセスできちゃいますよということです。
ではどうやってその機能を使うのか?順を追って説明していきます。
ポインタ変数
以下のコードをみてください。
void hogehoge()
{
int var;
int *pointer;
}何もしません。変数だけが定義してあります。片方はint型の変数var、もう一つはint*型の変数pointerです。
これら二つは共に何かしらを入れるための箱(メモリ上に確保された領域)とだけ考えてください。この箱には何が入るか考えます。
int varは何を入れる箱か?
intとはCPUに依存した型です。32bit CPUの場合は32bit=4byteなので変数varは4byteのデータを入れる箱ということを示します。
int *pointerは何を入れる箱か?
*印に注目です。*がついているとポインタ変数と呼ばれる箱になります。ポインタ変数にはアドレス番地が格納されることを想定しています。
32bit CPUの場合、アドレスの範囲は0x00000000~0xFFFFFFFFの4byteなので、変数pointerも4byteのアドレス値というデータを入れる箱になります。
前にある型がintであろうとcharであろうとアドレス値は4byteなので、箱の大きさは4byteになる点も注意です。
ポインタ変数と変数の違い
上記のように、int varとint *pointerは両者共に同じ4byteの箱ということがわかりました。
では違いはなにか?それはプログラム上でできる機能が違います。
機能の違い1 アドレスへのアクセス
以下のようなコードを考えます。
void hogehoge_var()
{
int var;
var = 0x1000; // varの箱に0x1000を入れる
}
void hogehoge_pointer()
{
int *pointer;
pointer = 0x1000; // pointerの箱に0x1000を入れる
*pointer = 1; // アドレス0x1000番地にデータ1を入れることでアドレス0x1000番地のデータが変わる
}変数varの方は0x1000というデータを格納することしかできません。そしてvarを読みだしても入れたデータが読み出せるだけです。
一方ポインタ変数pointerは0x1000というデータを格納するだけにとどまらず、0x1000番地のアドレスに対してデータを読んだり書いたりすることもできます。
つまりポインタ変数に入っている値をアドレスと見立てて、そのアドレスに直接アクセスできるようになるのです。これがポインタ変数の一番大きな機能になります。
機能の違い2 変数の演算
変数とポインタ変数を足し算してみます。わかりやすく+1してみましょう。
void hogehoge_var()
{
int var;
var = 0x1000; // varの箱に0x1000を入れる
var += 1; // varの変数を+1する
// varの箱の中身は0x1001になります。
}
void hogehoge_pointer()
{
int *pointer;
pointer = 0x1000; // pointerの箱に0x1000を入れる
pointer += 1; // pointerの変数を+1する
// pointerの箱の中身は0x1004になります。
}varの箱の中身は0x1000+1で0x1001になるのは簡単にわかります。箱の中身に1足すだけです。
しかし、pointerの方は0x1004になってしまうのです。これは先ほど無視してよいといった*の前についてる型(ここではint)によるものです。
int *pointerのintは、pointerが指し示すアドレスにアクセスする際、どのようなサイズでアクセスするか表現しています。
このポインタを使ってアドレスの先のデータにアクセスした時、4byteまるっとデータを読み書きするということです。例えば1を書き込むと0x00000001が4byte分書き込まれます。
なのでポインタ変数pointerを+1するというのは、
「あなたは4byteでデータアクセスをするポインタでしょ?+1したら次の4byteのデータにアクセスできるようにアドレス値は+4しておきますね!」
ということを勝手にしてくれるC言語の計らいになります。これに足をすくわれてしまうことも多々ありました。油断すると変なアドレスになってしまうので注意が必要です。
ポインタ変数と変数の違いまとめ
ポインタ変数と変数の違いについて説明しました。違いを以下にまとめておきます。
| 変数 | ポインタ変数 | |
|
確保されれるメモリのサイズ |
変数の型に依存 |
CPUのアドレスサイズに依存 32bit CPU:4byte 64bit CPU:8byte |
| アドレスへの アクセス |
変数に格納したデータをアドレスとして使うことはできない | 変数に格納した値をアドレスと見立ててそのアドレスに指定した型でアクセスできる |
| 変数への演算 (加算減算) |
演算通りの値 |
ポインタの型のサイズ |
配列へのポインタアクセス
C言語には配列という概念があります。この配列もポインタと密接な関係があります。以下のコードはarrayという配列を定義しています。
void hogehoge_array()
{
int array[3]; // 4byteの箱を3つ確保
array[0] = 0; // 箱のindex 0に0を入れる
array[1] = 1; // 箱のindex 1に1を入れる
array[2] = 2; // 箱のindex 2に2を入れる
}arrayの配列数は3なので、int型(4byte)の箱が連続3個、計12byteのメモリ領域が確保されたことになります。
この配列の中に0,1,2と値を代入しています。この配列もメモリ上のどこかに配置されているので、配列自身もアドレスを持っています。
ここで、変数arrayをポインタ変数のように扱って、配列の中身を書き換えてみます。
void hogehoge_array()
{
int array[3]; // 4byteの箱を3つ確保
array[0] = 0; // 箱のindex 0に0を入れる
array[1] = 1; // 箱のindex 1に1を入れる
array[2] = 2; // 箱のindex 2に2を入れる
*array = 100; // 箱のindex 0に100を入れる
}*arrayに100を代入することは、array[0]に100を代入することと等価になります。すなわち、arrayという変数を配列の先頭のアドレスが格納されたポインタ変数として使用できるということです。
また、逆も可能です。ポインタ変数を配列のように[]をつけてindex指定でアクセスするやり方です。
void hogehoge_array()
{
int *array; // ポインタ変数定義
array = 0x1000; // array の箱に0x1000を入れる
array[0] = 0; // アドレス0x1000番地にint型の配列があるつもりでindex0にデータ0を入れる
array[1] = 1; // アドレス0x1000番地にint型の配列があるつもりでindex1にデータ1を入れる
}
このようにポインタ変数と配列は密接な関係にあります。インデックスなしの変数シンボルはポインタ変数と同じように扱えると覚えておきましょう。
構造体型のポインタ変数
最後に構造体とポインタについて説明します。構造体は必要なメンバーを集めたものを型として定義したものです。
以下のように構造体型の箱を確保して、メンバを指定して値をいれることができます。
typedef struct hoge{
int a;
int b;
int c;
} HOGE;
void hogehoge_HOGE()
{
HOGE hogehoge; // 構造体の箱を1つ確保
hogehoge.a = 0xa; // HOGE構造体のメンバaに0xaを入れる
hogehoge.b = 0xb; // HOGE構造体のメンバaに0xbを入れる
hogehoge.c = 0xc; // HOGE構造体のメンバaに0xcを入れる
}では、構造体型のポインタ変数はどのように扱うのでしょうか?構造体もintやcharと同じ用に構造体+*でポインタを宣言することができます。
void hogehoge_HOGE()
{
HOGE *hoge; // 構造体の箱を1つ確保
hoge = 0x1000; // hogeの箱に0x1000を入れる
hoge->a = 0xa; // 0x1000番地にHOGE構造体があるつもりでメンバaの番地に0xaを入れる
hoge->b = 0xb; // 0x1000番地にHOGE構造体があるつもりでメンバbの番地に0xbを入れる
hoge->c = 0xc; // 0x1000番地にHOGE構造体があるつもりでメンバcの番地に0xcを入れる
}*hogeは実際にHOGEの箱があるわけではなく、あくまでアドレスを入れるための箱なので、箱のサイズは4byteです。
hogeに0x1000を入れることで、0x1000番地にHOGE型の構造体に従ったデータがあるつもりでアクセスできます。
データがあるつもりというのは、あるかないかはこのコードをプログラムする人しか知りません。アドレス0x1000がそのデータ構造で領域を確保してあって、利用できる前提であることをプログラムする人がきちんと把握していないといけません。
また、メンバへのアクセスは[.]ではなく、[->]になります。これはポインタ変数からメンバにアクセスする時のルールになります。
まとめ
ポインタの機能はCPUにあるアドレスとデータという概念に基づいて、CPUを任意のアドレスにアクセスするC言語に備わった機能です。この機能を利用すれば、CPUのペリフェラルを制御したり、任意のメモリを書き換えたり読み出したりできます。
これを踏まえた上でC言語でポインタを扱う方法について説明しました。ここにある基礎を理解しておけば、いろいろと応用が利くかと思います。うまく説明できたかわかりませんが、少なくとも15年前の自分に見せたい内容が書けたかなと思います。

コメント